In early 2021, I wrote my Master’s Thesis with the title ‘Patterns of Preference When Listening to Unfamiliar Music’. The thesis was written in collaboration with the Music Lab and under guidance from Dr. Samuel Mehr (The Music Lab, Harvard University) and Prof. Dr. Eric-Jan Wagenmakers (University of Amsterdam).
Abstract
This thesis explores the question of what it is that makes people like the music they hear, by analysing over 1.5 million ratings of musical preference by more than 200,000 people from around the world. By examinining preferences in unfamiliar and foreign music, many of the pitfalls that come with studying familiar music are avoided, providing unique insights into musical preference. The results show that (1) variations in preference between different countries or languages are dwarfed by variations between different songs or participants and (2) increased genre familiarity is linked with increased preference, opening up the possibility of preferences for local music being largely driven by familiarity and prior exposure. Results also highlight how existing theories of musical preference struggle to account for many of the observed relationships: melodic and rhythmic complexity were linearly related to preference, putting the theory of an inverted U relationship into question. At the same time, the relationship between clarity of a song’s function and preference was strongly modulated by a song’s intended function, questioning theories of prototypicality-related preference. Evidence for a relationship between preference and closeness to a Zipfian distribution was inconclusive. Machine learning algorithms were able to predict mean song preference well, but struggled to accurately predict individual ratings of preference. They also highlighted the importance of form and function ratings by naïve listeners in predicting preference, which may serve as a promising direction for future, theory-building research. These results raise questions concerning the nature of musical preferences, highlighting the importance of studying unfamiliar music to better understand the underlying factors of musical preference.
Key Findings
A subset of figures from the thesis, illustrating key results, can be found below.
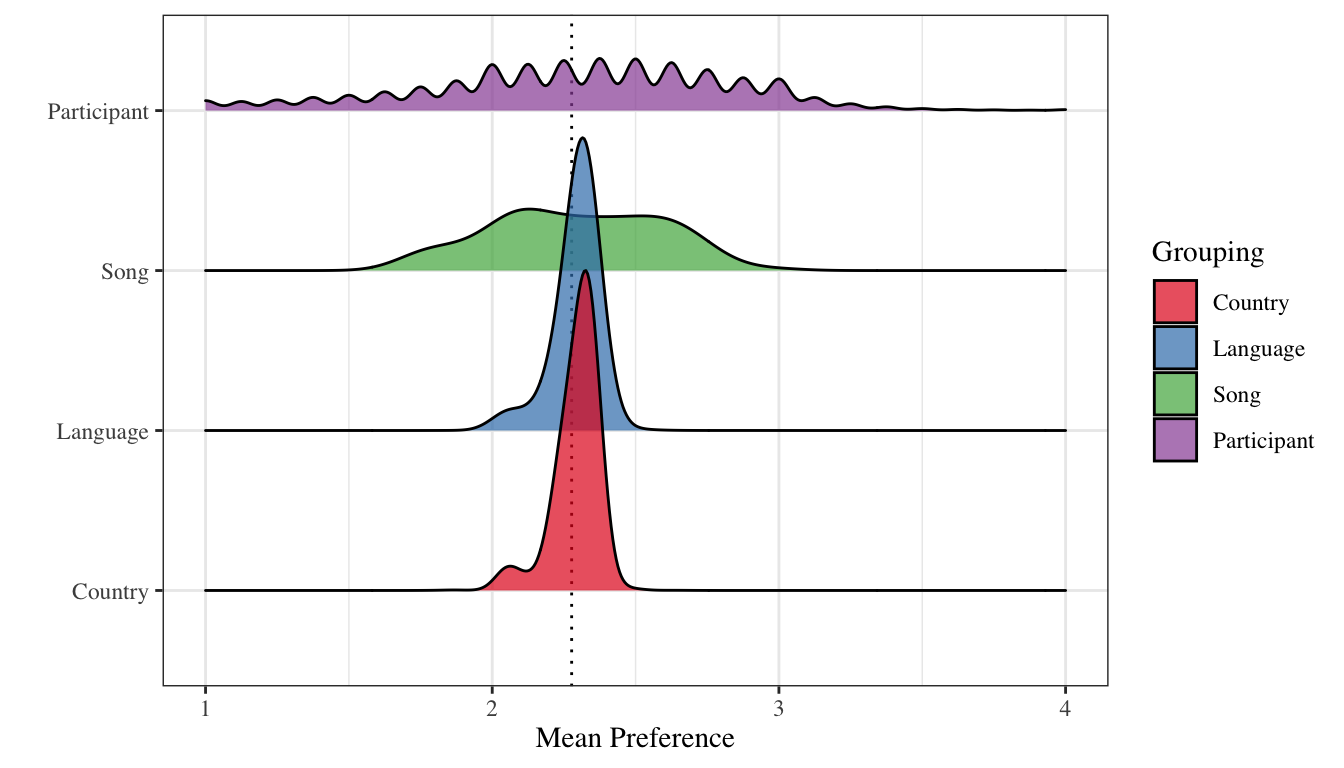
Mean preference ratings for different participants and songs are much more variable than mean preference ratings for different countries or languages. Distribution of mean preference ratings for different participants, songs, countries and languages. Visualized using kernel density estimates weighted by the number of observations in each group. Riffles in the distribution of mean preference ratings for different participants are due to limits in precision caused by the number of ratings per participant. The dotted line corresponds to the global mean preference ratings across all participants, songs, countries and languages.
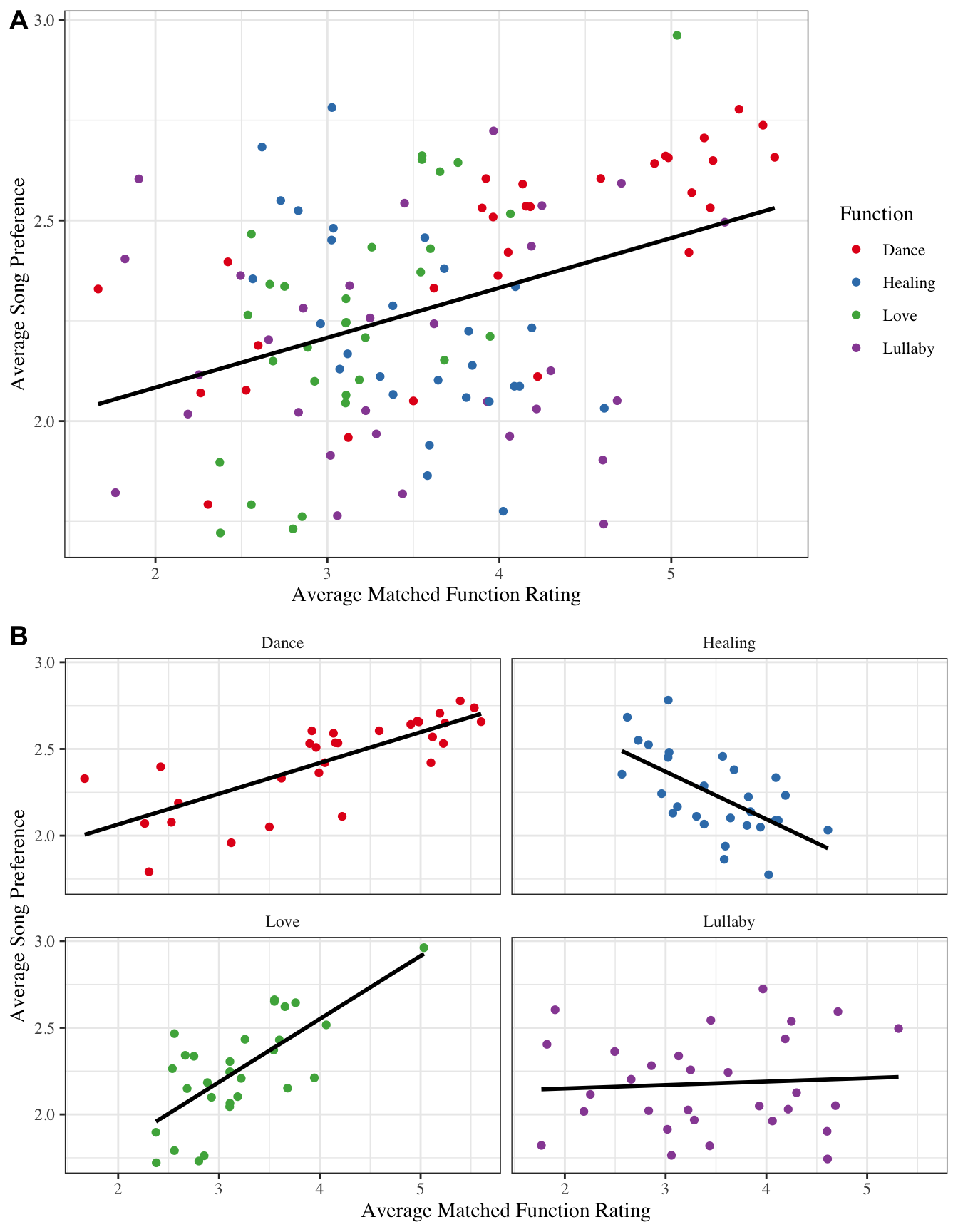
Ratings for a song’s intended function and preference are positively correlated overall, but start differing widely when split by a song’s intended function. Naïve listener’s mean ratings for a song’s intended function and mean preference ratings. Individual songs’ intended function is denoted by their color. Lines correspond to linear models estimated across all songs (A) and separately for songs split by their originally intended function (B).
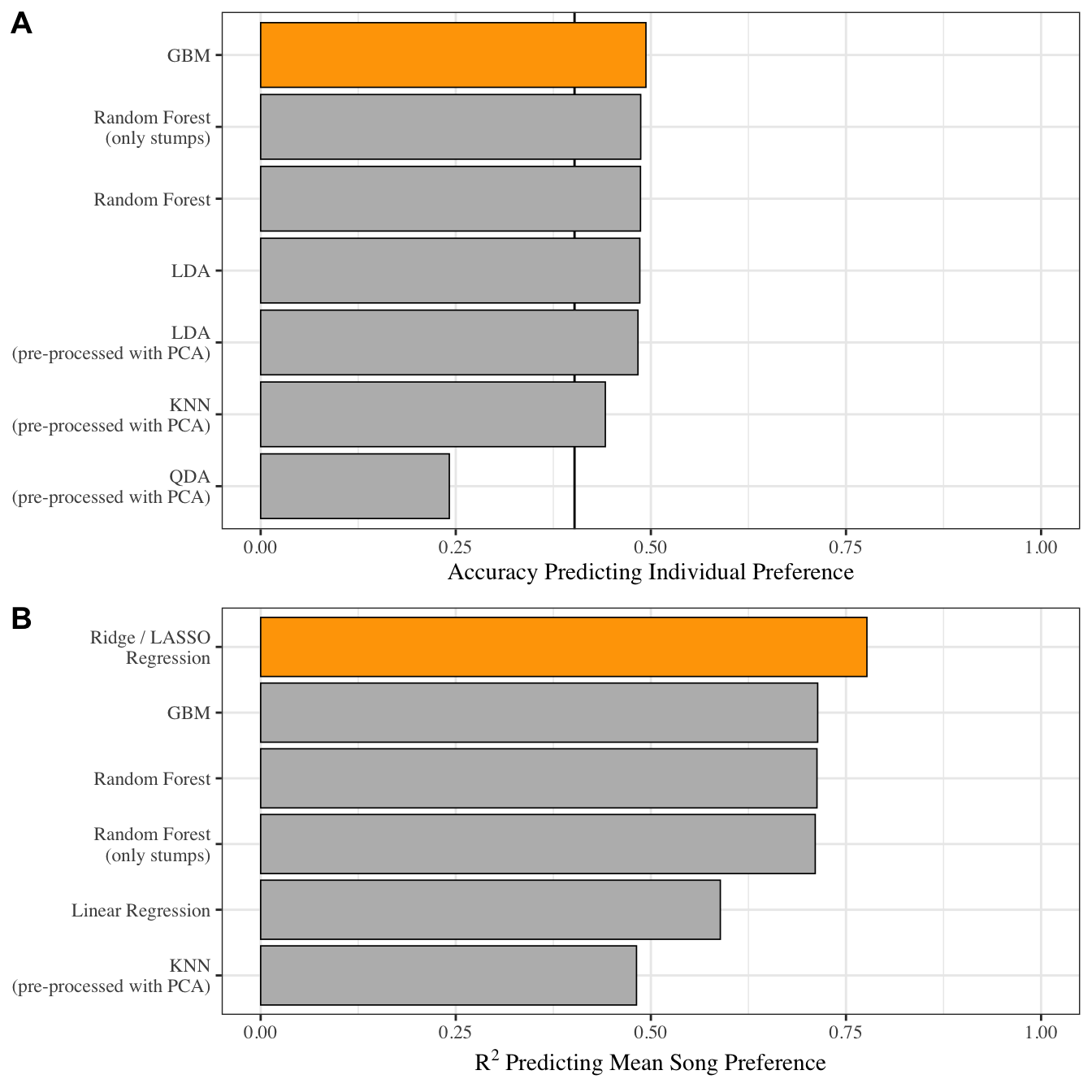
Machine learning algorithms struggle to accurately predict individual ratings beyond baseline, but perform well when predicting mean song preference. Performance of different machine learning models predicting individual preference ratings (A) and mean song preference ratings (B). The best performing model is highlighted in each case. The black lines denotes baseline accuracy for models predicting individual ratings, when only the most common rating were to be predicted.
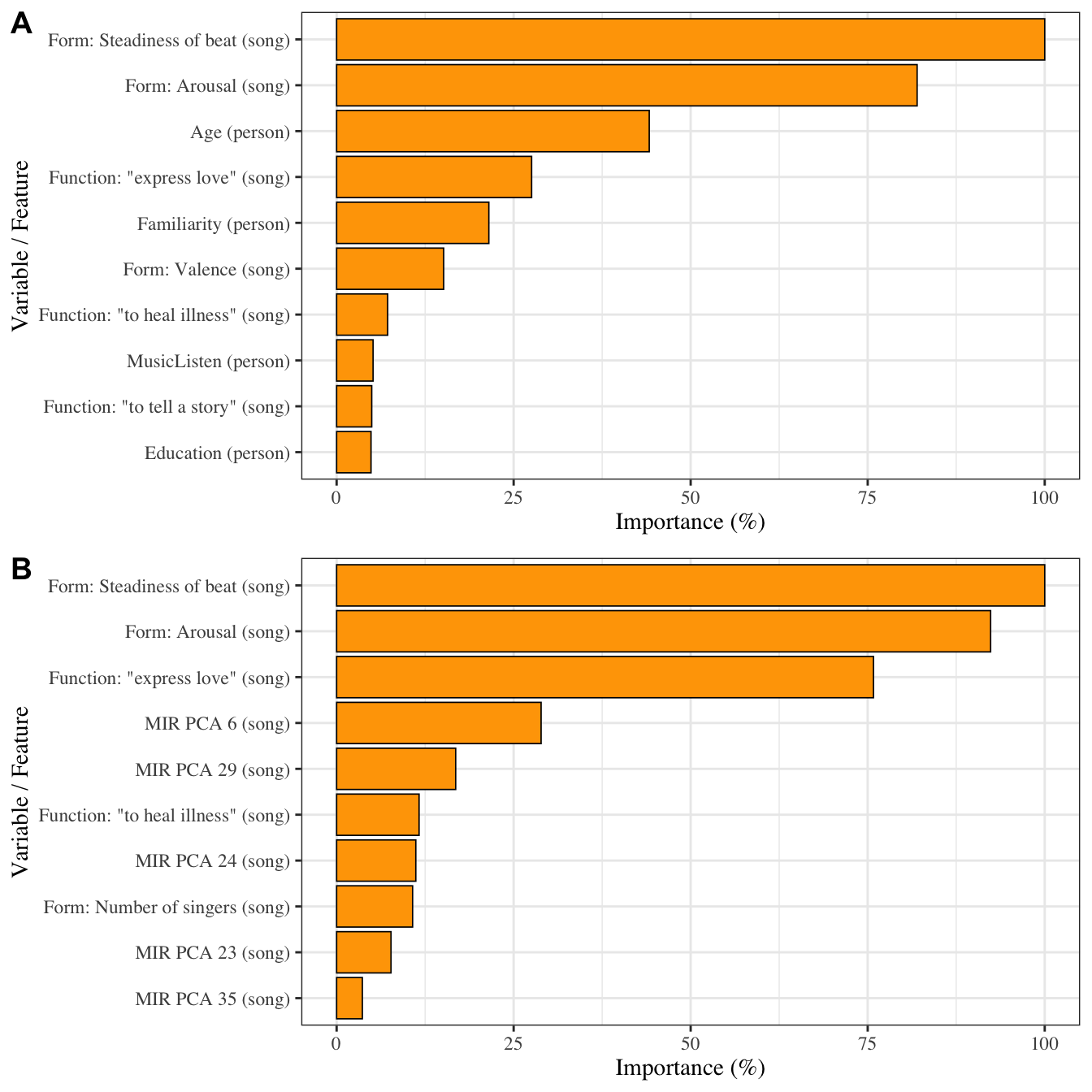
Naïve listener ratings of musical form and function are among the most important predictors when predicting individual as well as mean song preference. The 10 most important features in the best performing machine-learning models predicting individual preference ratings (A) and mean song preference (B). Labels in brackets denote whether a feature varies on the person- or song-level. When predicting mean song preference, only song-level features were used. Features are ordered by their relative importance.
Unique Challenges
The size of the data used in this project provided unique opportunities as well as challenges. Some of the analyses in the thesis had to be performed on the Harvard Cannon research cluster, while others had to be adjusted in order to be able to run in a reasonable amount of time even with access to a computing cluster.