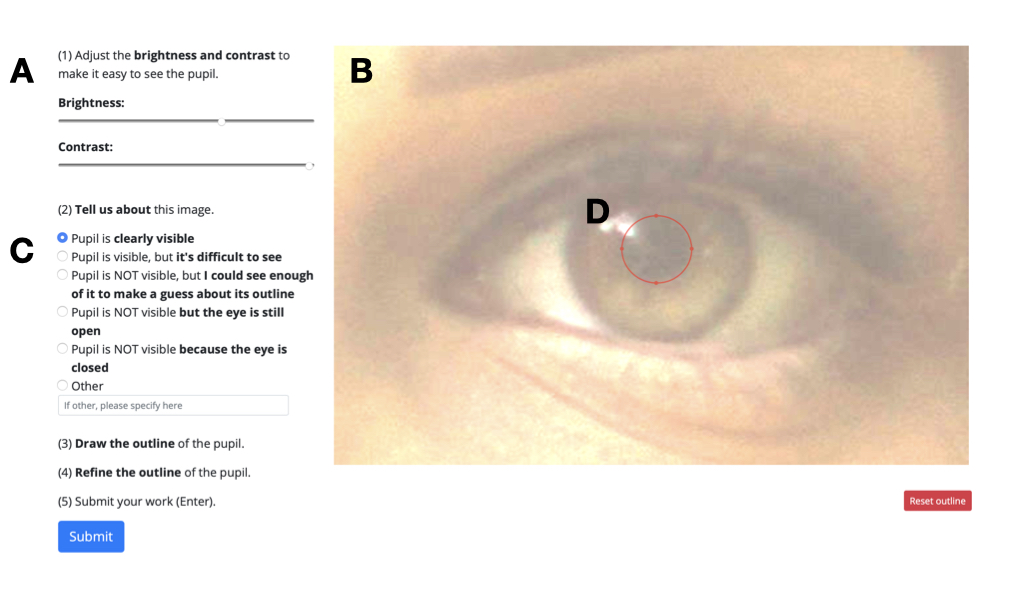
During my time at the Harvard Music Lab, I’ve worked on creating a python toolbox to automatically extract and measure pupil size from videos. This tool is currently still being developed, however in the process I’ve built a manual annotation tool which has already been used in a project at the lab that is published in Nature Human Behaviour. The first draft of the automated version of the tool achieved a median intersection over union / Jaccard-Index of ~0.75 using a convolutional neural network.
technology used
The toolbox is being developed in python. It uses opencv for image extraction and face_recognition (powered by dlib) to detect facial features in the extracted images. For the automated pupil extraction keras, tensorflow and keras-image-segmentation are used to try and segment the images of eyes into pupil and non-pupil pixels. Data manipulation and tidying is done in pandas and R.